
Over the weekend I was reading Combine: Asynchronous Programming with Swift from my friends at raywenderlich.com when it occured on me that Combine and Core ML might make a nice couple.
Combine lets you build reactive event processing chains. Doing inference with a Core ML model can be one of the stages in such a chain, as this is nothing more than another data transformation operation.
In this blog post I’ll show a simple way to put Core ML inside a Combine event processing chain. You can find the code in this gist.
Keep in mind that I have a grand total of about 2 days experience writing Combine code, so there might be better ways to do this. 😅
Publishers, subscribers, operators
A typical processing chain for an image classifier looks something like this:
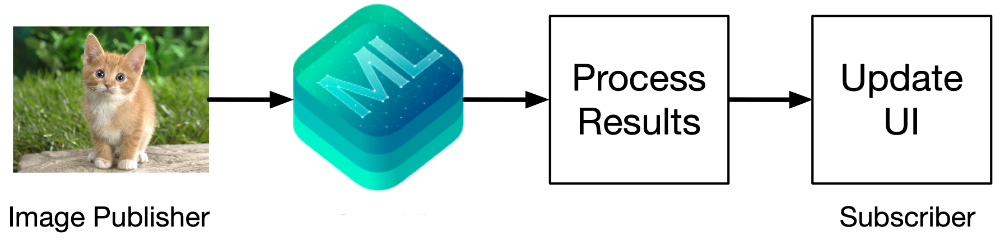
The first stage in this chain is a publisher, in Combine terminology, of images.
The last stage of the chain is a subscriber that takes the classification results and displays them in the app.
The in-between stages in the chain are operators. These subscribe to the previous publisher in the chain, transform the input they receive, and publish the results to the next subscriber in the chain.
For an image classifier, you want an operator that performs inference on the input image using Core ML. This is followed by an operator that filters the results you’re interested in from the model’s prediction, for example the top-5 classes with the highest confidence scores.
In this blog post you’ll see how to create a custom Combine operator that lets you run any kind of Core ML model. There are actually several additional stages in the processing chain, but this is the general idea.
Tip: Want to know more about how Combine works? Read the book! 😁 Combine isn’t very well documented right now — and can be mind-boggling if you haven’t done reactive programming before — but the team at raywenderlich.com did a great job at making the topic accessible.
Get yourself a model
For this blog post I’m assuming we’re working with an image classifier — but the same technique works for any kind of model, even ones that don’t use images.
The model I’m using in the sample code is SqueezeNet, the 16-bit version. You can download it from developer.apple.com/machine-learning/models/. Feel free to use any other image classifier model instead.
Create an instance of the model using the Xcode-generated helper class:
let squeezeNet = SqueezeNetFP16()
It starts with an image…
Because SqueezeNet is an image classifier, it makes sense to start the processing chain with an image object. Core ML likes to work with CVPixelBuffer objects, but let’s say you have a UIImage instead.
You can create a publisher for images as follows:
let imagePublisher = PassthroughSubject<UIImage, Never>()
Now you can write imagePublisher.send(someImage) to send the UIImage object down the processing chain. Pretty easy.
You could also use a different publisher here. For example, the UIImage could come from an event chain involving the UIImagePickerController, or from an event chain that downloaded the image using NSURLSession, or from any other publisher that outputs image objects.
Or you could publish a CGImage or a CVPixelBuffer object instead of UIImage. And if your model expects a multi-array input, you’d use a publisher that produces MLMultiArray objects.
The whole point of Combine is that you can put all these different building blocks together in whatever specific way makes sense for your app.
The goal in this blog post is to run the Core ML model on the UIImage coming from the imagePublisher. As you may know, Core ML does not directly accept UIImage objects as input so we’ll have to convert it to a CVPixelBuffer somehow. That will be one of the stages in the processing chain.
Before we get into that, let’s look at how we’re going to run Core ML using Combine in the first place.
The prediction operator
We need to create a Combine operator that lets us perform inference using a Core ML model and capture the output.
We want to be able to write something like the following:
imagePublisher
.prediction(model: squeezeNet)
.sink { value in print(value) }
The prediction operator is what runs the given Core ML model. This operator is connected to the imagePublisher, which is where it gets the input image from. In turn, it sends the prediction results to the sink subscriber, which displays them to the user — in this case, by printing the value to debug output.
Every time you call imagePublisher.send(someImage), this processing chain is automatically executed.
We’ll actually need to make the processing chain a bit more complicated than the above, but first let’s look at how to implement this new prediction operator.
Here is the code:
extension Publisher where Self.Output: MLFeatureProvider {
public func prediction(model: MLModel)
-> Publishers.Map<Self, Result<MLFeatureProvider, Error>> {
map { input in
do {
return .success(try model.prediction(from: input))
} catch {
return .failure(error)
}
}
}
}
There are several ways to create a new Combine operator, but this is the easiest. You simply add a new function to the Publisher namespace. (An operator is both a publisher and a subscriber.)
Combine really loves generics, and getting the type signature correct is half the battle of writing a new operator. Let’s examine what all these types mean…
To make this a general-purpose operator that works with any Core ML model, we’re using the MLModel API, not the helper class that Xcode automatically generates for you. (The generated helper code is specific to a particular model and won’t work with a different model.)
The key thing to know about the MLModel API is that the input data must be given by an MLFeatureProvider object, and the output data also gets placed inside an MLFeatureProvider.
If you look at the automatically generated class for SqueezeNetFP16, you can see the input and output helper classes indeed do conform to MLFeatureProvider:
class SqueezeNetFP16Input: MLFeatureProvider {
...
}
class SqueezeNetFP16Output: MLFeatureProvider {
...
}
Because the input data for the MLModel must be contained in some type that conforms to MLFeatureProvider, we’ve defined the new prediction operator so that it only can be used with publishers whose output is an MLFeatureProvider:
extension Publisher where Self.Output: MLFeatureProvider {
That’s what the where Self.Output: MLFeatureProvider thing does. It tells Swift you can only call prediction() in a processing chain if the previous element in the chain outputs an MLFeatureProvider.
The next line in the code was:
public func prediction(model: MLModel)
-> Publishers.Map<Self, Result<MLFeatureProvider, Error>> {
A Combine operator is a function on a publisher that returns a new publisher object. It’s important to get the return type correct.
We’re simply reusing an existing publisher type, Publishers.Map, that is the result of performing a map operation on the processing chain. After all, doing inference with a Core ML model is really nothing more than a transformation on some data — and that’s exactly what map does too.
The Publishers.Map object takes two generic types:
First, the type of the upstream publisher, which is
Self. The upstream publisher is the one whose output you’re runningprediction()on.The second type is
Result<MLFeatureProvider, Error>. This describes the output from the Core ML model.
If all goes well, the Core ML output is a new MLFeatureProvider object that contains whatever the model computed. However, things don’t always go well. In that case, Core ML throws an error.
There are different ways in which you can handle errors with Combine. Normally, if an error is thrown in a Combine processing chain, the subscription is “completed” in a failure mode and the subscriber no longer receives any events. I don’t really like that for Core ML errors, so another way to handle potential error situations is to return a Result object.
Actually running the Core ML model is done by this code:
map { input in
do {
return .success(try model.prediction(from: input))
} catch {
return .failure(error)
}
}
Here, map is the Combine operator that converts the input, which is the MLFeatureProvider object provided by the upstream publisher, into a Result object that will be sent downstream.
We simply run the usual MLModel prediction() method and either return a Result.success with the output MLFeatureProvider or a Result.failure with the thrown Error object.
It’s now up to any other stages in the processing chain to figure out how to handle the Result object, and to deal with the error in case it’s a .failure.
If you always want to silently ignore errors, you can write the prediction operator using compactMap instead of map, like so:
public func prediction(model: MLModel)
-> Publishers.CompactMap<Self, MLFeatureProvider> {
compactMap { input in try? model.prediction(from: input) }
}
Now if Core ML gives an error, try? returns nil and compactMap will ignore such results — they don’t get pushed any further down the processing chain. Note that the return type is different now too. We’re returning a Publishers.CompactMap object; and Result isn’t needed because things can never go wrong.
It’s also possible to use tryMap to complete the subscription upon the first error:
public func prediction(model: MLModel)
-> Publishers.TryMap<Self, MLFeatureProvider?> {
tryMap { input in try model.prediction(from: input) }
}
In fact, you can have all three of these versions of prediction() in the code base. Swift can tell them apart based on the type of the input used in the next stage of the chain. For example, if the next stage expects an MLFeatureProvider? object, it’s obvious it should use the tryMap version of prediction().
Note: If you get an error message, “Ambiguous use of ‘prediction(model:)‘“, it means Swift has trouble figuring out which version of the operator to use. You may need to provide explicit type annotations to disambiguate.
Building the chain
At this point, we’ve got two parts of the processing chain:
- the publisher that provides
UIImageobjects - the operator that can run inference using a Core ML model
But we can’t connect these two things together just yet. This won’t work:
imagePublisher
.prediction(model: squeezeNet.model)
.sink(receiveValue: { value in
print(value)
})
The problem is that imagePublisher produces UIImage objects but, as you’ve seen in the previous section, prediction() expects to receive an MLFeatureValue (because of the generics constraint we put on Self.Output).
If you tried to type in the above code, Xcode’s autocomplete does not suggest prediction as a valid thing after imagePublisher., which is a good hint that the two cannot be directly connected.
What we need is some way to convert the UIImage into an MLFeatureProvider object.
This is not limited to image classifiers, by the way. Since we’re using the MLModel API to run Core ML, all input data must be put into MLFeatureProvider, also if it’s an MLMultiArray or integers or strings or anything else.
Each piece of input data must first be converted to MLFeatureValue, and all the MLFeatureValues for a given prediction request need to be placed into the same MLFeatureProvider object.
Also, recall that Core ML wants a CVPixelBuffer object, not a UIImage. There are ways to convert from UIImage to CVPixelBuffer, but as of iOS 13, you can directly use a handy API on MLFeatureValue.
Here’s how to do it:
let inputName = "image"
let imageConstraint = squeezeNet.model.modelDescription
.inputDescriptionsByName[inputName]!
.imageConstraint!
let imageOptions: [MLFeatureValue.ImageOption: Any] = [
.cropAndScale: VNImageCropAndScaleOption.scaleFill.rawValue
]
imagePublisher
.compactMap { image in // 1
try? MLFeatureValue(cgImage: image.cgImage!,
orientation: .up,
constraint: imageConstraint,
options: imageOptions)
}
.compactMap { featureValue in // 2
try? MLDictionaryFeatureProvider(dictionary: [inputName: featureValue])
}
.prediction(model: squeezeNet.model)
The conversion from UIImage to MLFeatureProvider is split up into two steps:
First we load the image into an
MLFeatureValue. This API takes theUIImage— or actually itsCGImage— and scales it to the image dimensions the model expects. It can also rotate the image if it’s not upright. The scaled and rotated image is stored in anMLFeatureValueobject. For each input in your model, you need to provide such anMLFeatureValue.All the feature value objects for your model’s inputs are placed into a single
MLFeatureProvider. This is done in the second step. We use a concrete implementation,MLDictionaryFeatureProvider, that takes a dictionary that maps theMLFeatureValueobjects to the model’s named inputs. There’s only one input in SqueezeNet, named"image", but if your model has multiple inputs you’d specify them all in this dictionary.
For both of these steps we’re using the compactMap operator, so that if the try? fails and returns nil, the rest of the chain silently ignores the error. You can use tryMap instead in case you want such errors to propagate down the chain.
Now that the UIImage is wrapped in an MLFeatureProvider, you can finally call prediction() to perform inference.
Note that you can also replace the second compactMap with the following:
.map { featureValue in
SqueezeNetFP16Input(image: featureValue.imageBufferValue!)
}
This uses the Xcode-generated helper class, SqueezeNetFP16Input, which as you’ll recall implements MLFeatureProvider. This can’t go wrong, so you can use map here instead of compactMap. (The helper class actually expects the image as a CVPixelBuffer, which you can get from the MLFeatureValue object using the imageBufferValue property.)
If your model uses an MLMultiArray as input, or if your images aren’t UIImage, you’ll naturally need to change how the input data gets mapped. You can use any Combine operators here, just make sure that the input to prediction() is an MLFeatureProvider of some kind.
Note: When you call prediction(), you need to pass in an MLModel instance. You can’t use the squeezeNet variable, which is an instance of the auto-generated helper class SqueezeNetFP16. Instead, you need to write squeezeNet.model to get the MLModel object.
Processing the results
Depending on which version of prediction() you use, its return value is either an MLFeatureProvider, the optional version of that, or a Result object.
Actually, at this point in time it could still be any one of these… Swift doesn’t have enough information yet to decide which one to use. The next stage in the chain will determine this.
For example, if you write the following,
imagePublisher
/* conversion from UIImage to MLFeatureProvider omitted */
.prediction(model: squeezeNet.model)
.map { result -> String in
switch result {
case .success(let featureProvider):
return featureProvider.featureValue(for: "classLabel")?
.stringValue ?? "error"
case .failure(let error):
return error.localizedDescription
}
}
.sink(receiveValue: { value in print(value) })
Swift will use the prediction() that returns a Result object, because the switch statement obviously expects a Result here. Inside this map operation, we convert the prediction result into a string. The sink subscriber at the very end of the chain simply prints this string to the debug output.
The above works fine but it’s still a bit messy, especially the code needed to read the results from the MLFeatureProvider object:
featureProvider.featureValue(for: "classLabel")?.stringValue ?? "error"
Yuck. The whole reason Xcode generates the helper classes is to hide this nastiness from you, so let’s use those helpers as much as possible:
imagePublisher
/* conversion from UIImage to MLFeatureProvider omitted */
.prediction(model: squeezeNet.model)
.compactMap { try? $0.get() } // 1
.map { SqueezeNetFP16Output(features: $0) } // 2
.map { $0.classLabel } // 3
.sink(receiveValue: { value in print(value) })
Here’s how this works:
The
.compactMapstep callsget()on theResultobject. If the result was successful, this returns theMLFeatureProviderobject. This does the same as the first case in the switch statement above.If the
Resultwas not successful, thetry?returns nil andcompactMapsilently ignores the error. As before, you can usetryMaphere too.The first
mapputs theMLFeatureProviderinside the generated helper class,SqueezeNetFP16Output. This makes the next step more convenient.Here you grab the
classLabelproperty from the helper class. This property contains the label of the class with the highest predicted probability. (If you’re not using SqueezeNet, this property may have a different name in your model.)
And finally, we use the sink subscriber to print the string to the debug output.
Note: You can of course combine the two map operations into one:
.map { SqueezeNetFP16Output(features: $0).classLabel }
The reason I used two different steps is that some models have more than one output, and you may only want to do the conversion to the helper class just once.
It’s easy enough to change the result processing: just replace the map operation with something else.
For example, if you wanted to get the dictionary of predicted probabilities for all classes instead of just the highest probability class label, you’d simply grab the $0.classLabelProbs property. Now the sink receives a dictionary of [String: Double] values instead of a string.
You may also want to do some additional post-processing on the prediction results. For example, here’s how you’d get the top-5 classes from the dictionary:
.map {
$0.classLabelProbs.sorted { $0.value > $1.value }.prefix(5)
}
For a model such as SSD that predicts offsets to anchor boxes, you could do the bounding box decoding here, and so on…
The complete chain
Here’s what the full source code looks like:
class MyClass {
let squeezeNet = SqueezeNetFP16()
let imagePublisher = PassthroughSubject<UIImage, Never>()
var subscriptions = Set<AnyCancellable>()
func setUpProcessingChain() {
let imageConstraint = squeezeNet.model.modelDescription
.inputDescriptionsByName["image"]!
.imageConstraint!
let imageOptions: [MLFeatureValue.ImageOption: Any] = [
.cropAndScale: VNImageCropAndScaleOption.scaleFill.rawValue
]
imagePublisher
.compactMap { image in
try? MLFeatureValue(cgImage: image.cgImage!,
orientation: .up,
constraint: imageConstraint,
options: imageOptions)
}
.map { featureValue in
SqueezeNetFP16Input(image: featureValue.imageBufferValue!)
}
.prediction(model: squeezeNet.model)
.compactMap { try? $0.get() }
.map { SqueezeNetFP16Output(features: $0) }
.map { $0.classLabelProbs.sorted { $0.value > $1.value }.prefix(5) }
.sink(receiveCompletion: { completion in
print("Received completion event")
}, receiveValue: { value in
print("Received value:", value)
/* do something with the predicted value here */
})
.store(in: &subscriptions)
}
func performInference(image: UIImage) {
imagePublisher.send(image)
}
}
setUpProcessingChain() should be called just once to set everything up. And now you have a Combine processing chain that, every time you send it a UIImage object with imagePublisher.send(image), will automatically run a Core ML model on that image and process the results. Pretty cool!
Conclusion
Should you use this technique? It certainly makes sense if you’re using Combine elsewhere in your app.
Since the prediction() operator works like any Combine operator — it’s just a convenient wrapper around map — you can put it into any of your Combine processing chains.
For even more convenience, you could even implement conversion from UIImage (or whatever) to MLFeatureProvider as another operator:
imagePublisher
.toFeatureProvider(image: someImage)
.prediction(model: ...)
.postprocessPredictionResults()
.sink { ... }
As I write this, I haven’t used Combine much yet, and definitely not in a real app, but it looks like an interesting way to do reactive programming on iOS devices. And now it works with Core ML too!
Note: This blog post showed only a very simple implementation of prediction() that blocks the current thread. To perform the Core ML request asynchronously, it’s probably a good idea to write a custom Publisher class. But that’s a topic for another day.
First published on Wednesday, 13 November 2019.
If you liked this post, say hi on Twitter @mhollemans or LinkedIn.
Find the source code on my GitHub.
 New e-book: Code Your Own Synth Plug-Ins With C++ and JUCE
New e-book: Code Your Own Synth Plug-Ins With C++ and JUCE
Interested in how computers make sound? Learn the fundamentals of audio programming by building a fully-featured software synthesizer plug-in, with every step explained in detail. Not too much math, lots of in-depth information! Get the book at Leanpub.com