
So you’ve decided it’s time to add some of this hot new machine learning or deep learning stuff into your app… Great! But what are your options?
For many machine learning solutions, the approach is as follows:
- gather data
- use that data to train a model
- use the model to make predictions
Let’s say you want to make a “celebrity match” app that tells people which famous person they most look alike.
You need to first gather a lot of photos of celebrities’ faces. Then you train a deep learning network on these photos to teach it what each celebrity looks like.
The model you’re using would be some kind of convolutional neural network and you’ve trained it for the specific purpose of comparing people’s faces with the faces of celebrities.
Training is a difficult and expensive process. But once you have the trained model, performing “inference” — or in other words, making predictions — is easy.
You can give the model a selfie and it will instantly say, “You look 85% like George Clooney but you have Lady Gaga’s eyes!”

Exactly what data you need, what sort of model you should design, and how you should train this model all depend on the particular application you have in mind.
But you also need to make some choices about how to put your machine learning system into production. That’s what this blog post is about.
The main things you need to decide are:
- Do you want to train your own model?
- Do you want to train on your own computer or in the cloud?
- Do you want to do inference in the cloud or locally on the device (offline)?
In other words, should you use a cloud service to do the deep learning, or maybe roll your own? Let’s find out!
The quick & easy option
The first question to ask is: Do you even need your own model? By far the easiest way to get started is to use someone else’s model.
There is a growing number of companies that provide machine learning services tailored for specific purposes, such as speech recognition, text analysis, or image classification.
You don’t get access to their models directly — that’s their secret sauce — but you can use these models through an API.
Examples of such machine learning as-a-service providers:
- Clarifai
- Google Cloud Vision
- Amazon Rekognition, Polly, Lex
- Microsoft Azure Cognitive Services
- IBM Watson
and many others… these kinds of services are popping up all over.
If your app needs to perform one of the specific tasks offered by these services, you should definitely consider using them.
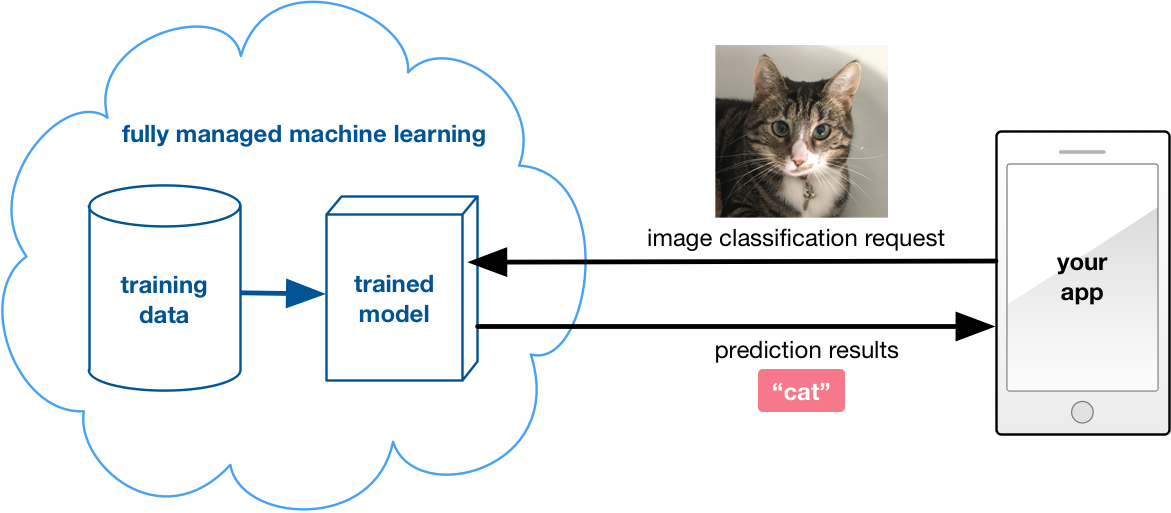
How this works: Your mobile app simply sends an HTTPS request to a web service along with any required data, such as a photo taken by the device’s camera, and within seconds the service replies with the prediction results.
Of course, you need to pay for this privilege, usually by the request. But you have nothing else to worry about: the only thing you need to do is talk to the service’s API endpoint from within your app. Often there is an SDK that makes the service easy to integrate.
The service provider keeps their model up-to-date by re-training it (using their own data), but this all happens behind the scenes. Any time they improve their model, you automatically benefit from it. You don’t have to know anything about machine learning in order to use these services.
Upsides of using such a “canned” machine learning service:
- It’s very easy to get started. (There is often a free tier.)
- Completely hands-off and hassle free. No worries about running your own servers or training models.
- You can benefit from machine learning without actually doing any of the hard work.
Downsides of this approach:
- You can’t perform inference locally on the device: all predictions are done by sending a network request to their server. This means there is a (short) delay between asking for a prediction and getting the results, and your app won’t work at all if the user has no network connection.
- You pay for each prediction request, something like $1 per 1000 requests.
- You can’t train on your own data, so this only works for fairly common data such as pictures, video, and speech. If there is something unique or special about your data, then this is not the right option for you.
Note: Some of these services may actually allow a limited kind of training. Clarifai, for example, lets you create your own model by uploading custom training images. This way you can augment their existing model to get better predictions for your own particular kind of images.
Using a fully-managed machine learning service is a great option if an existing model suits all your needs. For a lot of mobile apps this is the absolute right thing to do!
Training your own model
If your data is unique in some sense or existing solutions are not satisfactory, you’ll need to train your own model.
Data is key to doing successful machine learning. It’s the quality and quantity of the data that makes all the difference. If you’re going to do your own training, you need lots of data.
Once you have gathered your training data, the next decision is where and how to train. It depends on the complexity of your model and the amount of training data that you have.
- Small-ish model: you can train this on your desktop computer or on a spare machine you have lying around.
- Large model: a pimped-out machine with multiple GPUs will come in handy, but this really is a job for a high-performance computer cluster.
Unless you have your own data center or are rolling in cash, it makes most sense to rent computer power. There are many cloud platforms that are happy to take your money. These days you can even rent GPUs-in-the-cloud for training deep learning systems.
So it’s for you to decide: is renting cheaper than buying? However, there are other considerations besides price. Let’s look at some of those.
What about training on the device? If all the data you need to make predictions is available on the user’s device — and you don’t need data from other sources — then it might be an option to do the training on the device itself and not use the cloud at all. However, this will only work for small datasets and basic machine learning algorithms. It’s not something you can realistically do with deep learning.
Training in the cloud
There are two options here:
- general purpose cloud computing
- hosted machine learning
We’ll look at general purpose cloud computing first.
How this works: You rent one or more computers in someone else’s data center. Whatever you do on these computers is completely up to you. To train your model, you give the cloud computer access to your training data and run your favorite training software on it.
When you’re done training, you download the learned parameters for the model and delete the compute instance. You only pay for the compute hours used to train the model. Now you have a trained model that you can use anywhere you like.
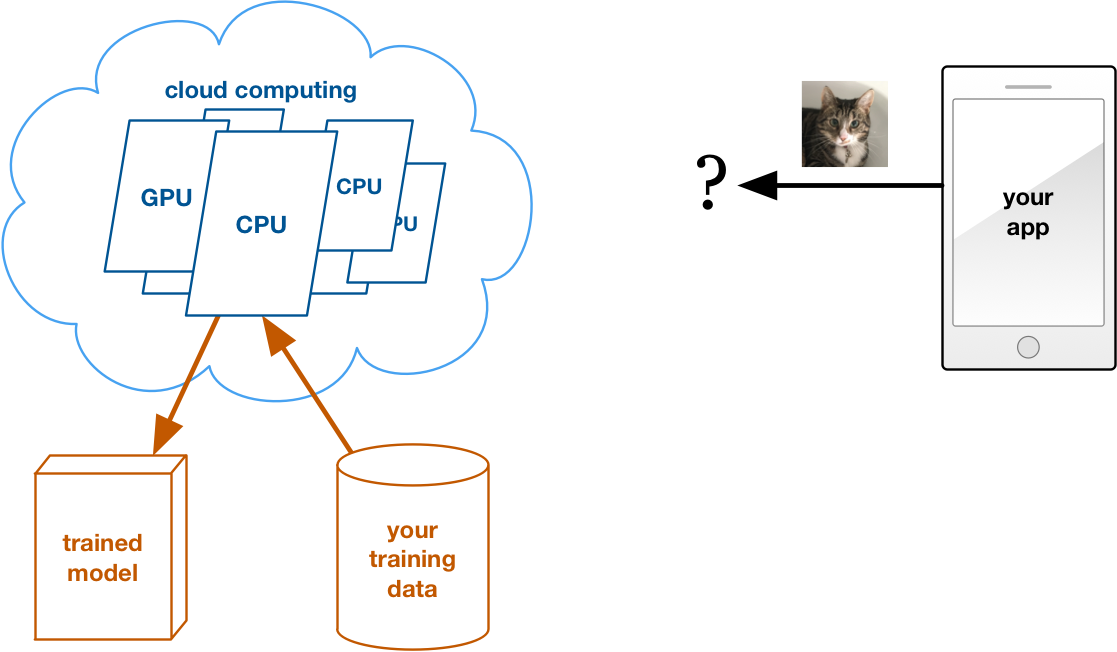
Examples of this kind of service are Amazon EC2 and Azure Virtual Machines. For deep learning you can even rent instances with fast GPUs.
Upsides:
- Ultimate flexibility, no responsibility. If you need more compute power, simply provision a few additional compute instances. That’s a lot cheaper than going out and buying new computers.
- Training is often done just once, so you only need to rent these computers for a limited amount of time. And if you want to re-train your model, you simply rent the computers again for a few hours or days.
- You’re not limited to training a specific type of model, and you can use your training package of choice.
- You can download the trained model and use it however you like.
Downsides:
- You need to know what you’re doing. Training the model is completely your own responsibility. If you’re not already well-versed in the art and practice of machine learning, you need to hire someone who is.
- You’ll need to upload your training data to the cloud service too. So not only do you pay for the compute hours, you also pay for storage.
Note: The above discussion only pertains to training the machine learning model, not to inference. Once you’ve trained your model you’ll need to make it available to the app somehow, so it can use the model for making predictions. If you decide to do this locally on the device then you just need to embed the model into your mobile app. But if you want to do inference in the cloud, you’ll still need to set up your own web service for inference. That comes with its own set of considerations (more about this below).
Hosted machine learning in the cloud
The other cloud option is hosted machine learning.
Several companies, such as Amazon, Microsoft, and Google, now offer machine learning as a service on top of their existing cloud services.
How this works: You don’t need to have the expertise to train models. You simply upload your data, choose the kind of model you want to use, and let the machine learning service take care of all the details.
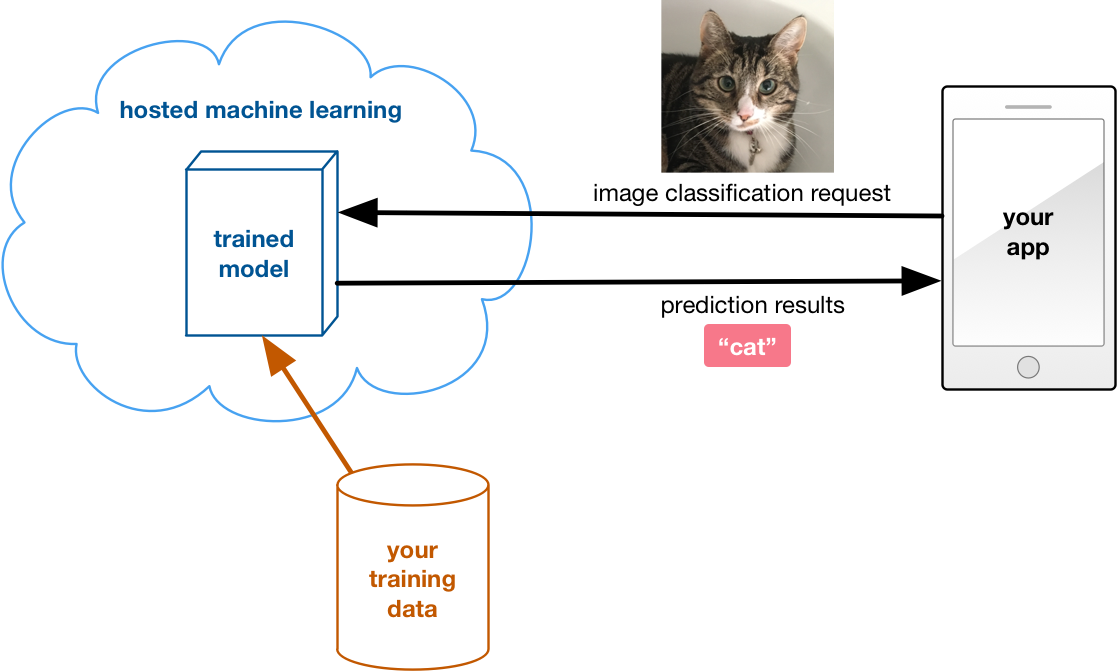
This option is the step between using a fully managed service and doing everything yourself. It’s definitely a lot easier than doing your own training, especially if you’re not really comfortable training your own models.
However… most of these services do not let you download your trained models. So for the inference part of your app you have no choice but to use their platform as well. You can’t take the trained model and load it onto a mobile device and run the predictions on the device itself. You always need to call their API and send along the user’s data for doing inference.
This may not be a problem for your app but it is something to be aware of before you get started. For example, when using Microsoft Azure Machine Learning you’re basically locked into using Azure forever. If you want to switch to another service, you can’t take your trained model with you — you’ll have to train from scratch on the new platform and eat the cost for that again.
These kinds of services charge you for the compute hours you use during training, plus any storage for your training data. Since the service provides the API that your app uses to request predictions, you also pay for each prediction request.
Upsides of using a hosted service:
- Just upload the data and don’t worry about the training.
- It’s easy to integrate these services into your app. You can’t do inference offline, but at least it’s easy to get the web service side of things up and running.
Downsides:
- You need to use their service for doing inference, you can’t do it offline on the mobile device itself.
- You may only have a limited number of models to choose from, so there’s less flexibility. For example, Amazon Machine Learning currently only supports linear regression and logistic regression. You can’t train a deep learning model with their service.
- The big companies — Amazon, Microsoft, Google — have a wide array of cloud services. To use their machine learning service, you also need to use their storage service, their SQL service, etc. You will have to upload your training data to the cloud service as well, and pay for this separately. So you really have to buy into their whole ecosystem.
Note: A pleasant exception here seems to be Google’s new Cloud Machine Learning platform (currently in beta). Like its competition, this cloud service lets you train your models (and if you want deploy them). But you can also export your trained model, which lets you do predictions offline. If you’re a TensorFlow fan this service seems like a great option. Then again, TensorFlow also runs on Amazon and Azure compute instances, and it’s always worth comparing prices.
Training on your own computers
How this works: This is really no different from training in the cloud, except that you use one or more computers that you own. You load your favorite machine learning package on the computers, give them access to your data, and set them off training.
If you’re really serious about deep learning, or if you happen to have a number of spare computers lying around anyway, then this option might be cheaper (in the long run) than renting someone else’s computer.
Tip: Even if you want to train in the cloud, it’s smart to start out with a reduced dataset on your own computer to make sure the model works correctly. Once you’re satisfied the model will give useful predictions, move on to training with the full dataset on a more powerful computer.
One issue with training in the cloud is that you need to upload your data to the cloud service. Since digital storage is their business, these cloud companies usually provide good security for your data. However, your data may be so sensitive that you don’t want it to leave your premises. In that case, you’ll need to do the training in-house as well.
Upsides:
- Total control. You can train however you want, whatever you want.
- You own the trained model, and you can deploy it any way you see fit: as a cloud service or offline on the device.
- You don’t pay rent for using someone else’s computer or cloud storage.
Downsides:
- You do pay for the hardware, software, electricity, and everything else it takes to keep your own computers running.
If your model is small enough, training on your own hardware is a sensible choice. However, for big models with lots of training data, using a cloud service makes it easier to scale up quickly should you need more resources.
Recap: training options
Using a “hosted” machine learning service — where you provide your own data but the service takes care of training — has the big disadvantage that you don’t own the trained model. If you use such as service, you’ll also have to use their web API for doing predictions.
So if you want to train on your own data and be able use the trained model offline, then you are limited to these options:
- train on your desktop or on another computer you own
- train in the cloud by renting someone else’s computer or compute cluster (such as Amazon EC2) but not using their hosted machine learning service
- use a service such as Google Cloud Machine Learning that lets you train in the cloud but also lets you download the trained model
You’ll definitely want to compare pricing between the different service providers. Most cloud services are very similar in the features they offer, so you might as well pay as little as possible. 💰💰💰
Note: Another thing to consider is how often you need to re-train. Only occasionally, in which case you just go through the same process again, or will you be retraining the model constantly? Not all hosted machine learning providers support online learning. And if you do online learning in the cloud, you’ll be renting those computers for a long time. If you run the numbers for this scenario, it might turn out to be less expensive to train on your own hardware after all.
Inference: making predictions
For training it’s pretty obvious that it should happen off-device, whether it’s on your own computers or on computers that you rent.
But for inference you have the choice of doing it on the device, without requiring a network connection.
Let’s look at the options:
If you’re using a canned service such as Clarifai or Watson, then you need to make a network request to their servers. Not much choice there.
If you’re using a hosted machine learning service such as Azure Machine Learning, then you also need to make a network request to their servers. You’ve trained the model with your own data, but the model lives on their servers and you don’t get access to it except through the web API.
If you trained the model yourself, you own the model’s learned parameters. You can decide whether to do inference on a server or on the device.
As with everything, whether it’s better to use a server or to do inference locally on the device, depends on a few tradeoffs.
One tradeoff could be speed: is it faster to run inference on the (relatively slow) mobile device, or is it quicker to send a network request to a fast and beefy server, do the inference there, and then send a reply back?
And some inference tasks are just going to be impossible on the device — it simply may not have enough processing power or RAM, or it may be limited by some other constraint.
Which option is more practical totally depends on your use case.
Inference on the server
How this works: You set up a server — either your own machine or one that you rent in the cloud — and load your trained model onto it. The server publishes the endpoint for a web API that your app talks to over the internet.
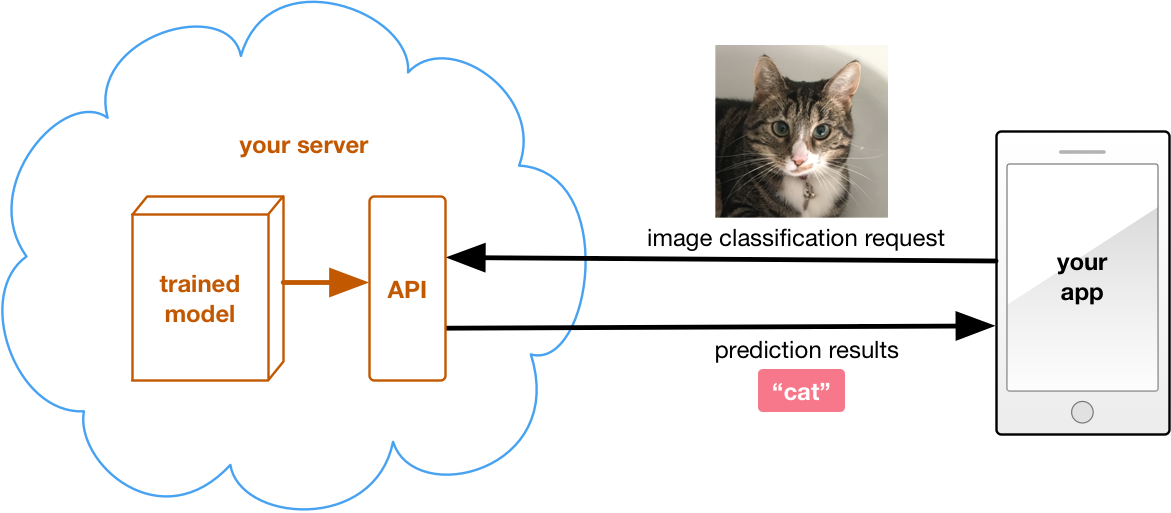
Suppose you have an app that turns a photo into digital art using deep learning. Users can choose different effects for their photos. The app sends the photo to the server, the server feeds the photo through the deep learning network to apply the desired effect, and a few seconds later it sends the modified image back to the app.
Using a server for inference keeps the mobile app simple. All the complexity is on the server, which is always under your control. You can improve the model or add new features any time you want. To deploy the improved model, simply update the server — you don’t have to update the app itself.
Upsides:
- If you already have a back-end for your app, then the inference logic can nicely integrate with your existing back-end.
- You can use the same software package for training and inference. (When doing inference locally on the device you may need to rewrite that logic in a different programming language.)
- Update the model any time you want.
- When all the machine learning logic is on the server, it’s easy to port the app to different platforms: iOS, Android, web, and so on.
- Your secret sauce is not embedded in the mobile app, so competitors cannot reverse engineer it.
Downsides:
- Users need to have network access in order to use this feature in your app.
- You need to run your own server. Even if you rent a server, you still need to deal with all the typical server headaches such as protecting against hackers, denial-of-service attacks, preventing downtime, and so on.
- You need to create your own API for processing prediction requests from clients. This includes things like handling authentication so that only authorized users can access the service.
- You pay for the bandwidth. All those photos people are sending to your server quickly add up to a lot of bytes flying through the pipe. If the server is your own machine, you also pay for the electricity bill.
- If your app becomes very popular, you may need to scale up to many servers. It’s not good for business if your app goes down because the servers are overloaded.
With a hosted machine learning service it only takes a click on a button to deploy the trained model to a web API. By creating and hosting your own API, you get more flexibility but the obvious downside is… well, that you need to do everything yourself.
If your app is a big success and has millions of (paying) users then it might be worth running your own inference backend. For many apps it’s probably cheaper and a lot less hassle to use a full-service machine learning in-the-cloud solution.
Note: Instead of rolling your own API from scratch you can also use existing tools, such as TensorFlow Serving.
Inference on the device
How this works: You load the model’s learned parameters into the app. To make a prediction the app runs all the inference computations locally on the device, on its own CPU or GPU — it does not need to talk to a server.
This is the domain of frameworks such as BNNS and Metal CNN on iOS, but some machine learning packages such as TensorFlow and Caffe also run on the device.

Speed is the major reason for doing inference directly on the device. You don’t need to send a request over the internet and wait for the reply — instead, the prediction happens (almost) instantaneously.
Take that same example of turning photos into “deep art”: what if you wanted to do this to a live camera feed in realtime? There is no way you can do this by sending network requests — it must be done directly on the device.
Note: To be fair, this is not a very realistic example. A lot of deep learning isn’t fast enough to do in realtime yet. But you get the point: for speed, you can’t beat local processing.
One of the big benefits of doing inference on a server is that you can put improved models into action immediately: upload the new model to the server and you’re done. With a mobile app this is not as straightforward, since you need to push out the improved model to all existing app installs somehow.
If you re-train the model often then you may need to set up some infrastructure for distributing the updated model parameters to the users’ devices. So you may need to keep a server around after all.
Upsides of doing inference on the device:
- Users can use the app even when they don’t have internet access.
- Speed: it can be a lot faster and more reliable than doing network requests.
- If inference happens on the device, then you don’t need to run servers. When the app becomes more popular and gets more users then there is no need for you to scale up anything, since there is no centralized bottleneck.
Note: Users now pay for the cost of doing inference with their own battery power. This may actually be a reason to not do inference on the device if the amount of battery power used is unreasonable and creates a bad user experience.
Downsides:
- Including the model in the app bundle will increase the size of the app download signficantly, often by many megabytes.
- It’s more difficult to update the model. Users need to download an app update to get the improved model, or the app needs to download it automatically.
- Porting the app to a different platform may be difficult, since you need to rewrite the inference part for each platform (and possibly for each device type).
There is another potential issue you need to be aware of: other developers can dig around inside your app bundle. It’s easy to copy over the learned parameters, and if you’re including a TensorFlow graph definition or caffemodel file it’s very simple for unscrupulous people to steal your entire model. You may want to obfuscate this data if having it gives you a competitive advantage.
Conclusion
As you can tell, there are lots of options to choose from!
And no doubt we’ll see many more machine learning services appear on the market in the coming months and years.
What’s best for your app and your business — and your users! — really depends on the kind of machine learning you’re doing, so it’s impossible to give tailored advice without knowing the exact details.
But at least I hope this blog post has given you an idea of the possibilities!
If you’re interested in learning more about doing deep learning on iOS devices, then get in touch and let’s chat. 😄
First published on Thursday, 16 February 2017.
If you liked this post, say hi on Twitter @mhollemans or LinkedIn.
Find the source code on my GitHub.
 New e-book: Code Your Own Synth Plug-Ins With C++ and JUCE
New e-book: Code Your Own Synth Plug-Ins With C++ and JUCE
Interested in how computers make sound? Learn the fundamentals of audio programming by building a fully-featured software synthesizer plug-in, with every step explained in detail. Not too much math, lots of in-depth information! Get the book at Leanpub.com